



Communication Is the Key: What Is Your Objective?
First and for most, we will work on the objective of the project. We will have this open discussion with our clients to see what problem they have that needs to be fixed. We are listening patiently and make drafts of how the process will start and continue. We will have a lot of back and forth follow up to make sure that our clients’ needs are understood and suitable strategies are taken to problem solve their requirements. The objective of this project was finding relationship between seed contents and the color of the seed.
You are producing seeds or you are a seed buyer. There are so many ingredients in those precious sources of food such as protein, carbohydrates, and micro nutrients. In this post, we want to show in simple words the approach Grain Data Solutions takes to apply data science techniques to find insights and correlations This post explain the steps we take generally in our data science projects
Approach
Our machine learning process includes data exploration, data cleaning, training model, validating the model, and finally interpretation.

To start with, we will do some exploratory data analysis and data cleaning to make ourselves familiar with the dataset. Your dataset might be very untidy, or you might have several ones that cannot be merged easily to each other. Or, you might have missing values in your datasets. No worries! We’ll take care of that part as well. Data will be visualized and aspects such as correlations, statistically significant differences, or principle components will be identified.
Following are some examples of visualization after cleaning the dataset including principle component analysis, interaction and correlation among the features.
After we clean the dataset and evaluate correlation among different features, we initiate training the model. So, what does training models mean exactly? In simple words, training models means algorithms learns from several labelled examples. The more samples you have, the better. We consider several machine learning algorithms, find the most appropriate ones, tune them and find the best. We separate data into training and test set. We fit the model on the training set, and then validate it on the test set. It should perform properly on both, so that we can validate the model.
The best model is not necessarily the most complicated. Depending on your data and business objectives, the performances of different models are evaluated. The accuracy of the model will be important, but there are some other factors to have in mind. For some businesses the amount of false positive that should be avoided is important. For some cases, it is really important to have false negative as low as possible. Furthermore, the interpretation phase is very important, because it helps to communicate the final result of the model to non-technical audiences in a simplified but clear manner.
Result
Now, let see what the machine learning process made at the end. We developed a model with 74% accuracy that shows the relationship between colors and the compounds in lentils. Figure s below show the compounds that are more important in making brown color in lentil, and how each of these important compounds affects the brown color of the seeds. This was based on a mathematical method from game theory and coded as Shapley library extension in python.
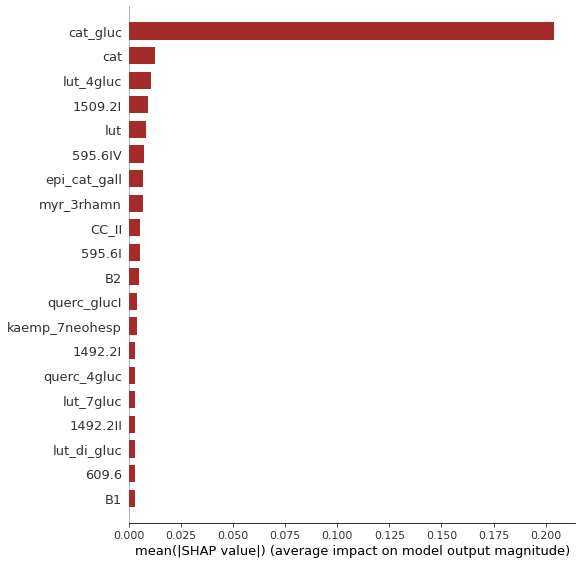
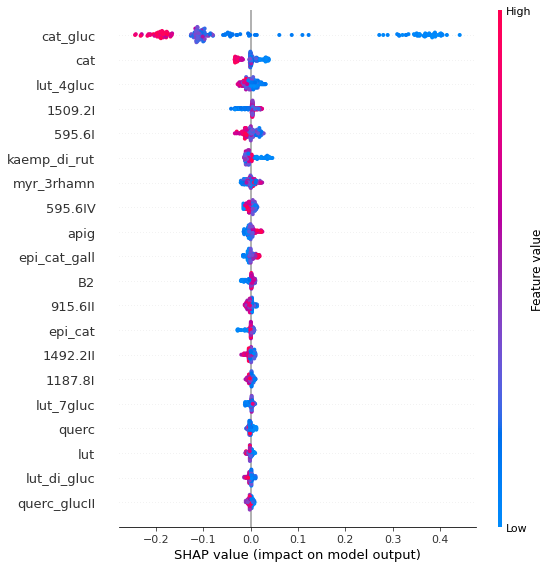
In this post we introduced application of machine learning process through a real example. Typical process will take a couple of weeks depends upon the datasets you have.